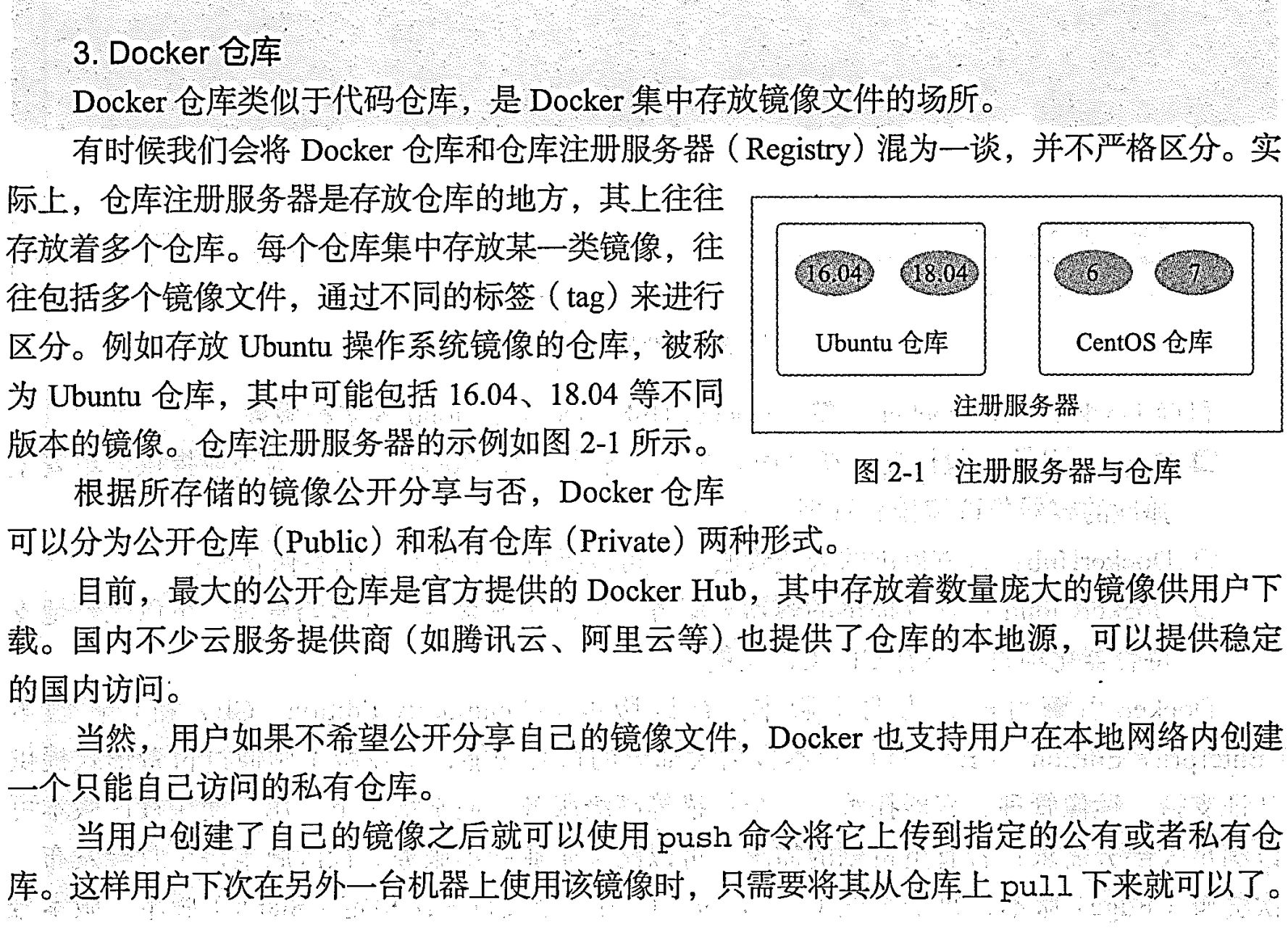
Docker 容器化
Docker 容器化
基础入门
虚拟化介绍
虚拟化的核心是对资源的抽象

Docker 为什么比虚拟化更加轻量?
传统方式是在硬件层面实现虚拟化,需要有额外的虚拟机管理应用和虚拟机操作系统
层。 Docker 容器是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,因此更加轻量级。
核心概念
Docker 镜像

容器

仓库
使用 Docker 镜像
pull

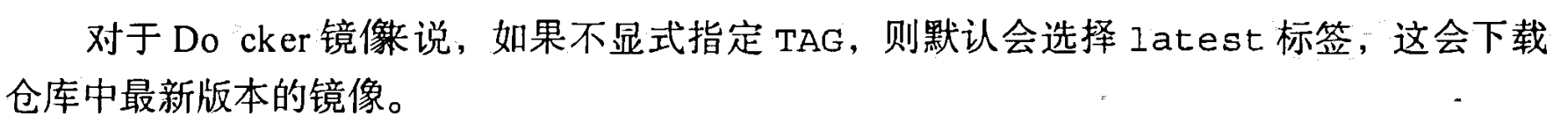 加上仓库地址
加上仓库地址

ls 、tag、 inspect
使用 images 命令列出镜像

使用 tag 命令添加镜像标签

使用 inspect 命令查看详细信息

docker search 搜索镜像

删除和清理镜像 rm 、prune
image rm 、rmi

prune

创建镜像
基于现有的容器创建|commit


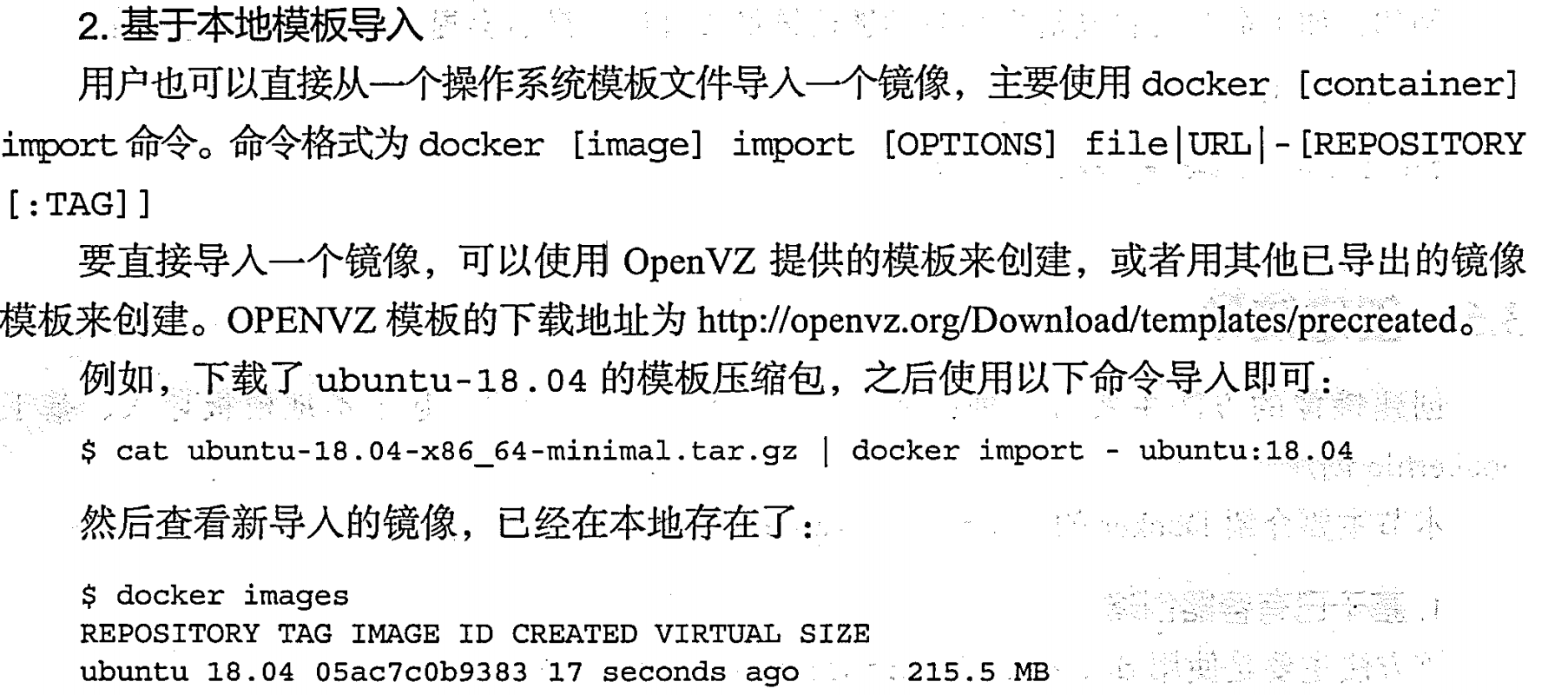
基于本地模板导入 | import
基于Dockerfile 创建|build

存出和载入镜像 |save、load

上传镜像 | push
注意要改tag为user/xxx

操作 Docker 容器
概要

创建和启动容器
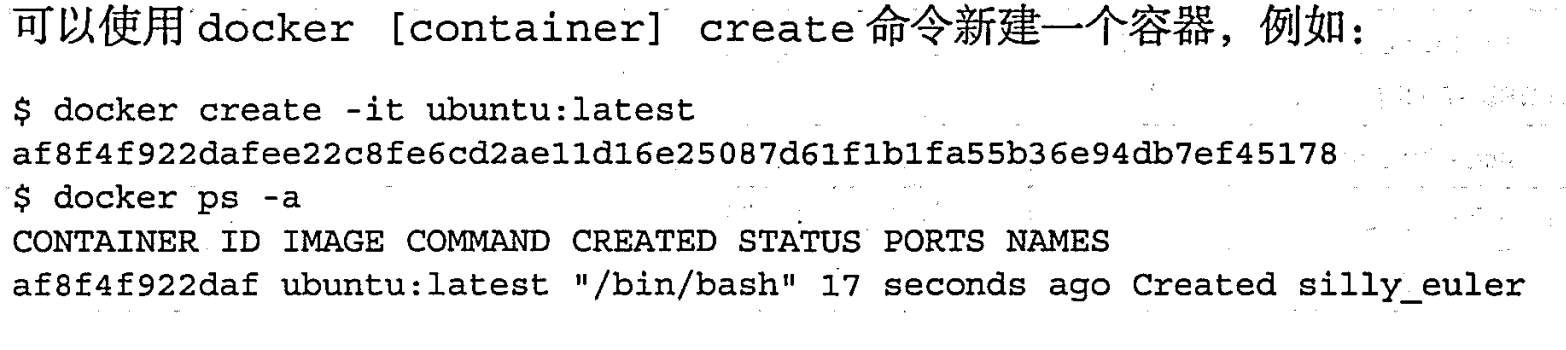
创建容器 |create
- -i 表示“交互式(interactive)”,它使容器的标准输入(stdin)保持打开状态,允许用户与容器进行交互,例如,可以输入命令并查看容器的输出。
- -t 表示“终端(terminal)”,它为容器分配一个伪终端(pseudo-TTY),使得用户可以在容器内部使用类似终端的功能,如执行命令、查看输出等。
启动容器 |start

新建并启动 |run
 当你在创建一个容器时使用 -it 选项并指定 /bin/bash,这意味着你要在新容器中运行 Bash shell,这样你就可以直接与容器进行交互,并在 Bash 提示符下执行命令和操作。
当你在创建一个容器时使用 -it 选项并指定 /bin/bash,这意味着你要在新容器中运行 Bash shell,这样你就可以直接与容器进行交互,并在 Bash 提示符下执行命令和操作。
run启动程序后台过程详解

守护态运行 | -d

查看日志 |logs

停止容器 |pause/unpause 、stop、 prune
暂停容器 | pause

停止容器 |stop

pause和stop区别?
主要区别在于,docker pause 会暂停容器的所有进程,保留容器状态;而 docker stop 会发送信号停止容器,允许容器内的进程完成清理并关闭容器。
- 停止容器会发送一个 SIGTERM 信号给容器内的主进程,然后等待一定的超时时间(默认为10秒),让容器的进程完成清理工作并停止。
- 如果在超时时间后容器的进程仍未停止,Docker 将发送一个 SIGKILL 信号给容器内的主进程,强制终止容器内的所有进程并停止容器。
进入容器
attach

exec

删除容器 | rm


导入和导出容器 | export 、import
导出容器 | export


导入容器 |import

查看容器 | inspect、top、status
查看容器详情|inspect

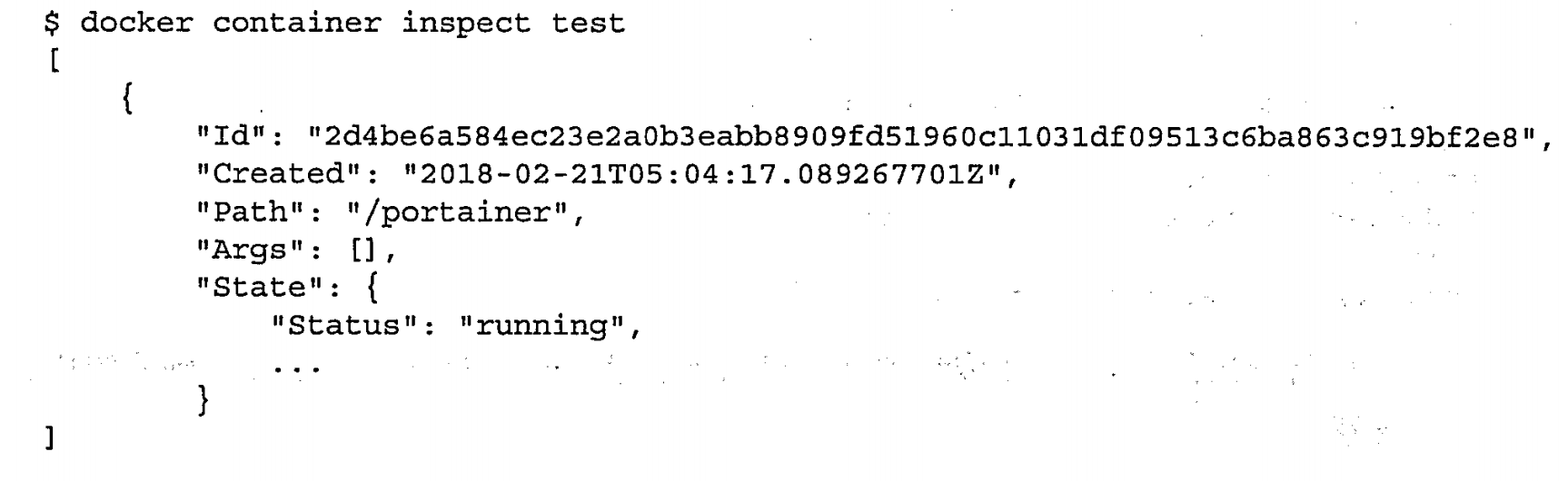
查看容器进程 |top

查看统计信息|stats

其他容器命令
复制文件|cp


查看变更|diff

查看端口映射|port

更新配置|updata
 例子:
例子:

Docker 数据管理

数据卷
创建数据卷|volume create

绑定数据卷|run -mount或者-v

数据卷容器


利用数据卷容器来迁移数据

端口映射和容器互联
端口映射实现容器访问|-p 2001:2001

容器互联实现交互
自定义容器命名|-name=xx1

容器互联|-link name:alias


核心实现技术(Docker 三大底座)

Namespace
 对于docker来说,最为直接的,是PID隔离
对于docker来说,最为直接的,是PID隔离
PID的命名空间隔离
当程序调用fork()函数时,系统会创建新的进程,为其分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的进程中,只有少量数值与原来的进程值不同,相当于克隆了一个自己。那么程序的后续代码逻辑要如何区分自己是新进程还是父进程呢?
fork()的神奇之处在于它仅仅被调用一次,却能够返回两次(父进程与子进程各返回一次),通过返回值的不同就可以进行区分父进程与子进程。它可能有三种不同的返回值:
- 在父进程中,fork返回新创建子进程的进程ID
- 在子进程中,fork返回0
- 如果出现错误,fork返回一个负值
clone
实现在宿主机上运行两个相同 PID 的进程呢?
这里就用到了 PID Namespaces,它其实是 Linux 创建新进程时的一个可选参数,在 Linux 系统中创建进程的系统调用是 clone()方法。
1
2
3
| int clone(int (*fn) (void *),void *child stack,
int flags, void *arg, . . .
/* pid_ t *ptid, void *newtls, pid_ t *ctid */ ) ;
|
源码层面理解 pid 隔离
Docker 的容器就是使用上述技术实现与宿主机器的进程隔离,当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec:
1
2
3
4
5
6
7
8
9
10
| func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf("linux spec namespaces: %v", err)
}
return &s, nil
}
|
在 setNamespaces 方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| // setNamespaces 根据指定的配置为容器设置命名空间。
func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error {
// Linux 容器中可用的命名空间:user、network、ipc、uts、pid
....
// 检查容器的 PID 模式是否设置为 "container"
if c.HostConfig.PidMode.IsContainer() {
// 创建一个 PID 命名空间并将其路径设置为容器的 PID 命名空间
ns := specs.LinuxNamespace{Type: "pid"}
pc, err := daemon.getPidContainer(c)
if err != nil {
return err
}
ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID())
setNamespace(s, ns)
} else if c.HostConfig.PidMode.IsHost() { // 检查 PID 模式是否设置为 "host"
// 从容器的规范中移除 PID 命名空间
oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid"))
} else {
// 为容器设置新的 PID 命名空间
ns := specs.LinuxNamespace{Type: "pid"}
setNamespace(s, ns)
}
return nil
}
|
所有命名空间相关的设置 Spec 最后都会作为 Create 函数的入参在创建新的容器时进行设置:
1
| daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
|
所有与命名空间的相关的设置都是在上述的两个函数中完成的,Docker 通过命名空间成功完成了与宿主机进程和网络的隔离
其他的操作系统基础组件隔离
不仅仅是 PID,当你启动启动容器之后,Docker 会为这个容器创建一系列其他 namespaces。
这些 namespaces 提供了不同层面的隔离。容器的运行受到各个层面 namespace 的限制。
Docker Engine 使用了以下 Linux 的隔离技术:
The pid namespace: 管理 PID 命名空间 (PID: Process ID).
The net namespace: 管理网络命名空间(NET: Networking).
The ipc namespace: 管理进程间通信命名空间(IPC: InterProcess Communication).
The mnt namespace: 管理文件系统挂载点命名空间 (MNT: Mount).
The uts namespace: Unix 时间系统隔离. (UTS: Unix Timesharing System).
网络隔离
所以 Docker 虽然可以通过命名空间创建一个隔离的网络环境,但是 Docker 中的服务仍然需要与外界相连才能发挥作用。
每一个使用 docker run 启动的容器其实都具有单独的网络命名空间,Docker 为我们提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
Bridge——网桥
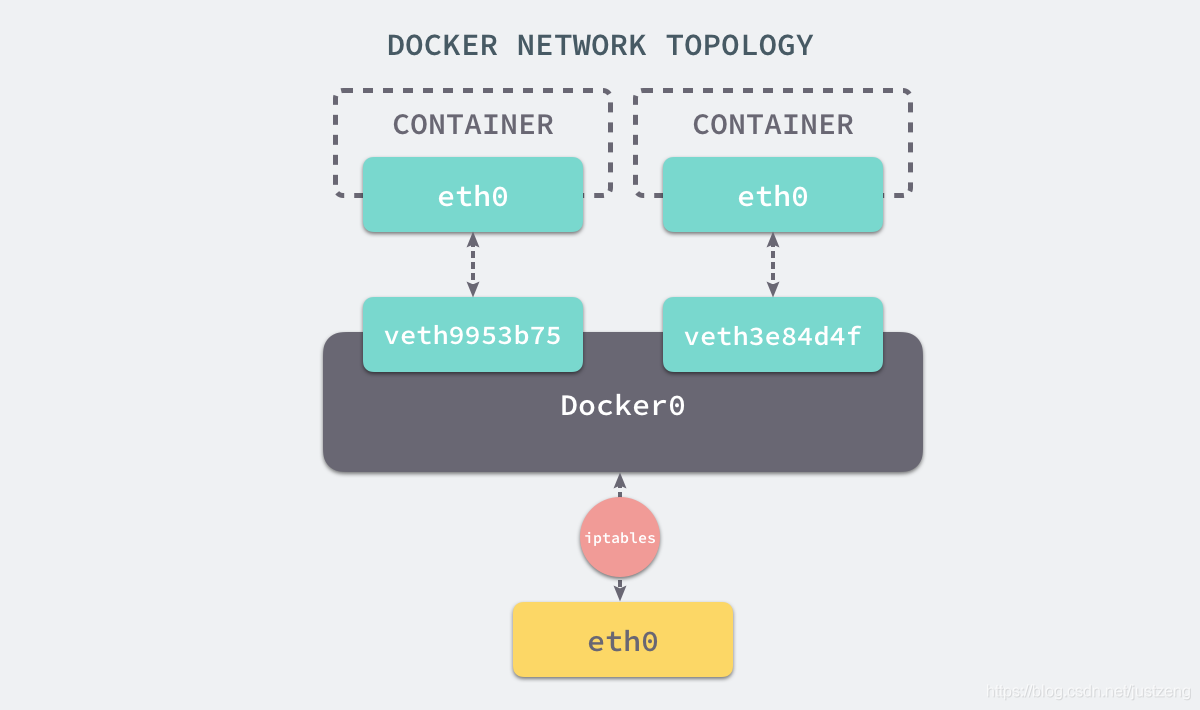 当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 docker0 网桥中
docker0会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。
网桥 docker0 通过 iptables (Linux中一个用于管理 IPv4 数据包过滤和网络地址转换的工具)中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
我们在当前的机器上使用 docker run -d -p 6379:6379 redis 命令启动了一个新的 Redis 容器,在这之后我们再查看当前 iptables 的 NAT 配置就会看到在 DOCKER 的链中出现了一条新的规则:
当 Docker 服务器在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。
默认情况下,每一个容器在创建时都会创建一对虚拟网卡,两个虚拟网卡组成了数据的通道,其中一个会放在创建的容器中,会加入到名为 docker0 网桥中
docker0会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。
网桥 docker0 通过 iptables (Linux中一个用于管理 IPv4 数据包过滤和网络地址转换的工具)中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
我们在当前的机器上使用 docker run -d -p 6379:6379 redis 命令启动了一个新的 Redis 容器,在这之后我们再查看当前 iptables 的 NAT 配置就会看到在 DOCKER 的链中出现了一条新的规则:
1
| DNAT tcp -- anywhere anywhere tcp dpt:6379 to:192.168.0.4:6379
|
上述规则会将从任意源发送到当前机器 6379 端口的 TCP 包转发到 192.168.0.4:6379 所在的地址上。
这个地址其实也是 Docker 为 Redis 服务分配的 IP 地址,如果我们在当前机器上直接 ping 这个 IP 地址就会发现它是可以访问到的:
1
2
3
4
5
6
7
8
| $ ping 192.168.0.4
PING 192.168.0.4 (192.168.0.4) 56(84) bytes of data.
64 bytes from 192.168.0.4: icmp_seq=1 ttl=64 time=0.069 ms
64 bytes from 192.168.0.4: icmp_seq=2 ttl=64 time=0.043 ms
^C
--- 192.168.0.4 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 999ms
rtt min/avg/max/mdev = 0.043/0.056/0.069/0.013 ms
|
从上述的一系列现象,我们就可以推测出 Docker 是如何将容器的内部的端口暴露出来并对数据包进行转发的了;当有 Docker 的容器需要将服务暴露给宿主机器,就会为容器分配一个 IP 地址,同时向 iptables 中追加一条新的规则。
Docker 通过 Linux 的命名空间实现了网络的隔离,又通过 iptables 进行数据包转发,让 Docker 容器能够优雅地为宿主机器或者其他容器提供服务。
挂载
虽然我们已经通过 Linux 的命名空间解决了进程和网络隔离的问题,在 Docker 进程中我们已经没有办法访问宿主机器上的其他进程并且限制了网络的访问,但是 Docker 容器中的进程仍然能够访问或者修改宿主机器上的其他目录,这是我们不希望看到的。
在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝,如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,所有二进制的执行都必须在这个根文件系统中。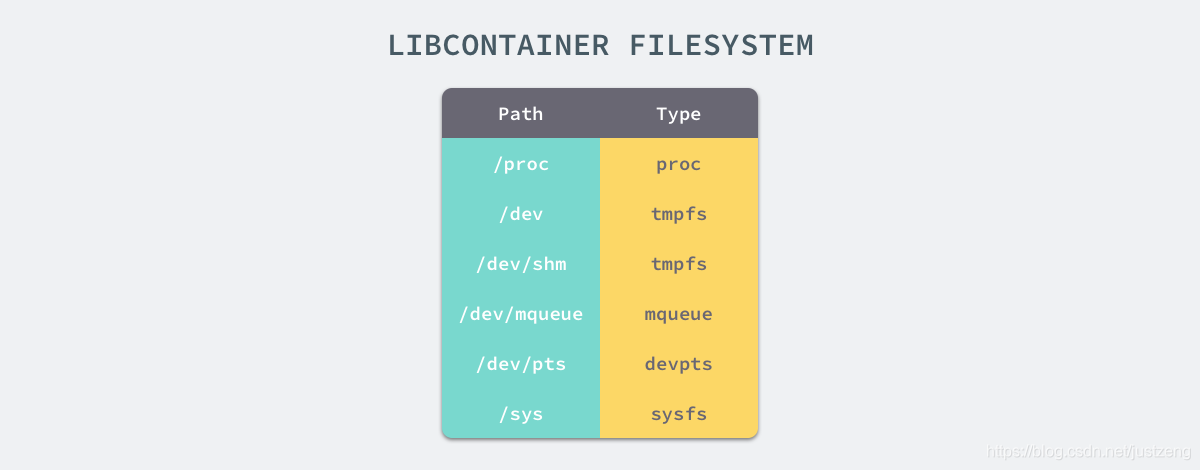 想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcotainer 提供的 pivor_root 或者 chroot 函数改变进程能够访问个文件目录的根节点。
想要正常启动一个容器就需要在 rootfs 中挂载以上的几个特定的目录,除了上述的几个目录需要挂载之外我们还需要建立一些符号链接保证系统 IO 不会出现问题。
为了保证当前的容器进程没有办法访问宿主机器上其他目录,我们在这里还需要通过 libcotainer 提供的 pivor_root 或者 chroot 函数改变进程能够访问个文件目录的根节点。
1
2
3
4
5
6
7
8
9
10
11
| // pivor_root
put_old = mkdir(...);
pivot_root(rootfs, put_old);
chdir("/");
unmount(put_old, MS_DETACH);
rmdir(put_old);
// chroot
mount(rootfs, "/", NULL, MS_MOVE, NULL);
chroot(".");
chdir("/");
|
到这里我们就将容器需要的目录挂载到了容器中,同时也禁止当前的容器进程访问宿主机器上的其他目录,保证了不同文件系统的隔离。
在这里不得不简单介绍一下 chroot(change root),在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构。
CGroups
命名空间并不能够为我们提供物理资源上的隔离,比如 CPU 或者内存,某一个容器正在执行 CPU 密集型的任务,那么就会影响其他容器中任务的性能与执行效率,导致多个容器相互影响并且抢占资源,而 Control Groups(简称 CGroups)就是能够隔离宿主机器上的物理资源
每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
Linux 的 CGroup 能够为一组进程分配资源,也就是我们在上面提到的 CPU、内存、网络带宽等资源,通过对资源的分配。
cgroups四大功能
- 资源限制:可以对任务使用的资源总额进行限制。
- 优先级分配:通过分配的cpu时间片数量以及磁盘IO带宽大小,实际上相当于控制了任务运行优先级。
- 资源统计:可以统计系统的资源使用量,如cpu时长,内存用量等。
- 任务控制: cgroup可以对任务 执行挂起、恢复等操作。
Docker 通过cgroup 来控制容器使用的资源配额,包括CPU、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制。
简介原理
而Cgroup的核心是一个叫做cgroupfs的文件系统,位于linux内核中的/sys/fs/cgroup目录下。该文件系统允许用户在一个层次结构中创建、管理和监控cgroup,具体实现如下
- 创建cgroup层次结构,这个层次结构由一个或者多个cgroup组成,每个cgroup都代表一组进程,并拥有一组资源限制。
- 将进程添加到cgroup中,这个实现其实就是把进程加到task文件中
- 为cgroup分配限制资源,例如可以用cgroup/cpu/相关的文件来限制cpu的使用率
- 监控cgroup的资源使用
UnionFS
UnionFS 其实是一种为 Linux 操作系统设计的用于把多个文件系统『联合』到同一个挂载点的文件系统服务。
AUFS 即 Advanced UnionFS 其实就是 UnionFS 的升级版,它能够提供更优秀的性能和效率。
AUFS 作为先进联合文件系统,它能够将不同文件夹中的层联合(Union)到了同一个文件夹中,这些文件夹在 AUFS 中称作分支,整个『联合』的过程被称为联合挂载(Union Mount)。
概念理解起来比较枯燥,最好是有一个真实的例子来帮助我们理解:
首先,我们建立 company 和 home 两个目录,并且分别为他们创造两个文件
1
2
3
4
5
6
7
8
| # tree .
.
|-- company
| |-- code
| `-- meeting
`-- home
|-- eat
`-- sleep
|
然后我们将通过 mount 命令把 company 和 home 两个目录「联合」起来,建立一个 AUFS 的文件系统,并挂载到当前目录下的 mnt 目录下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| # mkdir mnt
# ll
total 20
drwxr-xr-x 5 root root 4096 Oct 25 16:10 ./
drwxr-xr-x 5 root root 4096 Oct 25 16:06 ../
drwxr-xr-x 4 root root 4096 Oct 25 16:06 company/
drwxr-xr-x 4 root root 4096 Oct 25 16:05 home/
drwxr-xr-x 2 root root 4096 Oct 25 16:10 mnt/
# mount -t aufs -o dirs=./home:./company none ./mnt
# ll
total 20
drwxr-xr-x 5 root root 4096 Oct 25 16:10 ./
drwxr-xr-x 5 root root 4096 Oct 25 16:06 ../
drwxr-xr-x 4 root root 4096 Oct 25 16:06 company/
drwxr-xr-x 6 root root 4096 Oct 25 16:10 home/
drwxr-xr-x 8 root root 4096 Oct 25 16:10 mnt/
root@rds-k8s-18-svr0:~/xuran/aufs# tree ./mnt/
./mnt/
|-- code
|-- eat
|-- meeting
`-- sleep
4 directories, 0 files
|
通过 ./mnt 目录结构的输出结果,可以看到原来两个目录下的内容都被合并到了一个 mnt 的目录下。
默认情况下,如果我们不对「联合」的目录指定权限,内核将根据从左至右的顺序将第一个目录指定为可读可写的,其余的都为只读。那么,当我们向只读的目录做一些写入操作的话,会发生什么呢?
1
2
3
4
| # echo apple > ./mnt/code
# cat company/code
# cat home/code
apple
|
通过对上面代码段的观察,我们可以看出,当写入操作发生在 company/code 文件时, 对应的修改并没有反映到原始的目录中。
而是在 home 目录下又创建了一个名为 code 的文件,并将 apple 写入了进去。
看起来很奇怪的现象,其实这正是 Union File System 的厉害之处:
Union File System 联合了多个不同的目录,并且把他们挂载到一个统一的目录上。
在这些「联合」的子目录中, 有一部分是可读可写的,但是有一部分只是可读的。
当你对可读的目录内容做出修改的时候,其结果只会保存到可写的目录下,不会影响只读的目录。
比如,我们可以把我们的服务的源代码目录和一个存放代码修改记录的目录「联合」起来构成一个 AUFS。前者设置只读权限,后者设置读写权限。
那么,一切对源代码目录下文件的修改都只会影响那个存放修改的目录,不会污染原始的代码。
在 AUFS 中还有一个特殊的概念需要提及一下:
branch – 就是各个要被union起来的目录。
Stack 结构 - AUFS 它会根据branch 被 Union 的顺序形成一个 Stack 的结构,从下至上,最上面的目录是可读写的,其余都是可读的。如果按照我们刚刚执行 aufs 挂载的命令来说,最左侧的目录就对应 Stack 最顶层的 branch。
所以:下面的命令中,最为左侧的为 home,而不是 company
1
| mount -t aufs -o dirs=./home:./company none ./mnt
|
镜像分层
Docker Image 是有一个层级结构的,最底层的 Layer 为 BaseImage(一般为一个操作系统的 ISO 镜像),然后顺序执行每一条指令,生成的 Layer 按照入栈的顺序逐渐累加,最终形成一个 Image。
直观的角度来说,是这个图所示:
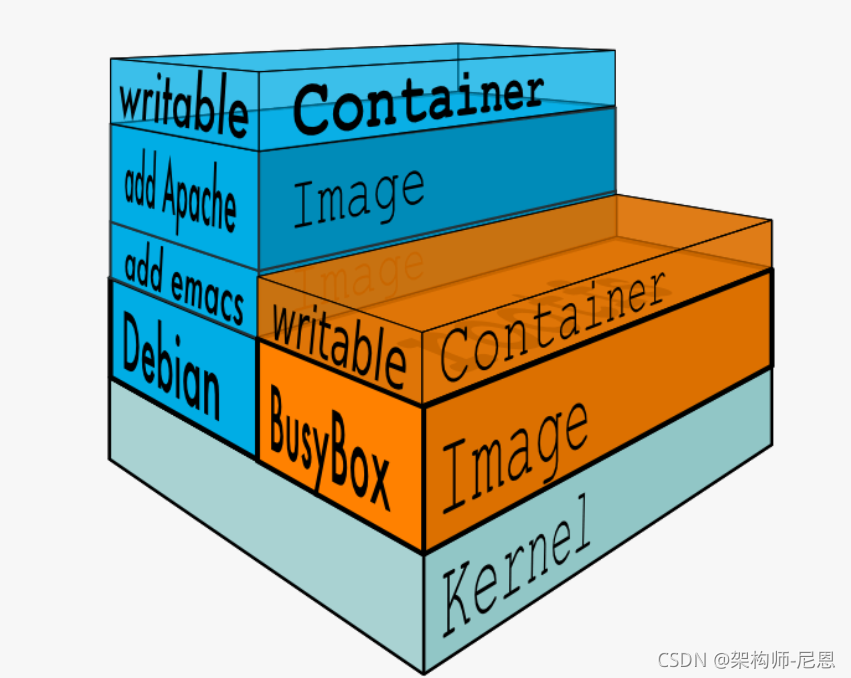
镜像的构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| root@rds-k8s-18-svr0:~/xuran/exampleimage# docker build -t hello ./
Sending build context to Docker daemon 5.12 kB
Step 1/7 : FROM python:2.7-slim
---> 804b0a01ea83
Step 2/7 : WORKDIR /app
---> Using cache
---> 6d93c5b91703
Step 3/7 : COPY . /app
---> Using cache
---> feddc82d321b
Step 4/7 : RUN pip install --trusted-host pypi.python.org -r requirements.txt
---> Using cache
---> 94695df5e14d
Step 5/7 : EXPOSE 81
---> Using cache
---> 43c392d51dff
Step 6/7 : ENV NAME World
---> Using cache
---> 78c9a60237c8
Step 7/7 : CMD python app.py
---> Using cache
---> a5ccd4e1b15d
Successfully built a5ccd4e1b15d
|
通过构建结果可以看出,构建的过程就是执行 Dockerfile 文件中我们写入的命令。构建一共进行了7个步骤,每个步骤进行完都会生成一个随机的 ID,来标识这一 layer 中的内容。 最后一行的 a5ccd4e1b15d 为镜像的 ID。由于贴上来的构建过程已经是构建了第二次的结果了,所以可以看出,对于没有任何修改的内容,Docker 会复用之前的结果。
如果 DockerFile 中的内容没有变动,那么相应的镜像在 build 的时候会复用之前的 layer,以便提升构建效率。并且,即使文件内容有修改,那也只会重新 build 修改的 layer,其他未修改的也仍然会复用。
Docker中的每一个镜像都是由一系列只读的层组成的,DockerFile中的每一个命令都会在已有的只读层上创建一个新的层,镜像的每一层其实都只是对当前镜像进行了部分改动,当镜像被docker run命令创建时,就会在镜像的最上层添加一个可读写的层,也就是容器层。
容器和镜像的区别就是 镜像只是可读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器
通过了解了 Docker Image 的分层机制,我们多多少少能够感觉到,Layer 和 Image 的关系与 AUFS 中的联合目录和挂载点的关系比较相似。
而 Docker 也正是通过 AUFS 来管理 Images 的。
Docker 实践
前提条件
安装
请自行搞定安装docker,docker-compose,portainer
https://docs.docker.com/get-docker/
potainer是服务器上用于可视化docker的,下面有个汉化的:
docker pull 6053537/portainer-ce
docker run -d -p 9000:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --name portainer 6053537/portainer-ce
dockerhub
去注册个账号,然后直接看这个吧
https://yeasy.gitbook.io/docker_practice/repository/dockerhub
dockerfile
先看一个小例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 使用官方的 Go 语言镜像作为基础镜像
FROM golang:latest
# 设置工作目录
WORKDIR /app
# 将当前目录下的所有文件拷贝到镜像的 /app 目录下
COPY . .
# 编译 Go 程序
RUN go build -o myapp .
# 指定容器运行时的命令
CMD ["./myapp"]
|
FROM 指定基础镜像
FROM 就是指定 基础镜像,因此一个 Dockerfile 中 FROM 是必备的指令,并且必须是第一条指令。除了选择现有镜像为基础镜像外,Docker 还存在一个特殊的镜像,名为 scratch。这个镜像是虚拟的概念,并不实际存在,它表示一个空白的镜像。
不以任何系统为基础,直接将可执行文件复制进镜像的做法并不罕见,对于 Linux 下静态编译的程序来说,并不需要有操作系统提供运行时支持,所需的一切库都已经在可执行文件里了,因此直接 FROM scratch 会让镜像体积更加小巧
RUN 执行命令
RUN 指令是用来执行命令行命令的。由于命令行的强大能力,RUN 指令在定制镜像时是最常用的指令之一。其格式有两种:
- shell 格式:RUN <命令>,就像直接在命令行中输入的命令一样。刚才写的 Dockerfile 中的 RUN 指令就是这种格式。
RUN echo ‘
Hello, Docker!
’ > /usr/share/nginx/html/index.html
- exec 格式:RUN [“可执行文件”, “参数1”, “参数2”],这更像是函数调用中的格式。
一些高级命令
看下面这个了解一下
https://yeasy.gitbook.io/docker_practice/image/dockerfile
多阶段构建镜像
全部放入一个 Dockerfile
一种方式是将所有的构建过程编包含在一个 Dockerfile 中,包括项目及其依赖库的编译、测试、打包等流程,这里可能会带来的一些问题:
- 镜像层次多,镜像体积较大,部署时间变长
- 源代码存在泄露的风险
分散到多个 Dockerfile
另一种方式,就是我们事先在一个 Dockerfile 将项目及其依赖库编译测试打包好后,再将其拷贝到运行环境中,这种方式需要我们编写两个 Dockerfile 和一些编译脚本才能将其两个阶段自动整合起来,这种方式虽然可以很好地规避第一种方式存在的风险,但明显部署过程较复杂。
而多阶段构建就可以解决上面的问题
现在来学习一下go-zero生成的dockerfile文件,安装一下goctl,然后输入:
goctl docker -go main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| # 构建阶段:使用 golang:alpine 作为基础镜像,起别名为 builder
FROM golang:alpine AS builder
# 设置阶段标签为 gobuilder
LABEL stage=gobuilder
# 设置环境变量:禁用 CGO 并配置 Go 代理
ENV CGO_ENABLED 0
ENV GOPROXY https://goproxy.cn,direct
# 替换 Alpine Linux 镜像源为阿里云镜像源
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories
# 更新并安装系统时区数据
RUN apk update --no-cache && apk add --no-cache tzdata
# 设置工作目录为 /build
WORKDIR /build
# 复制项目的 go.mod 和 go.sum 文件到工作目录
ADD go.mod .
ADD go.sum .
# 预下载 Go 模块的依赖
RUN go mod download
# 复制当前目录的所有文件到工作目录
COPY . .
# 编译项目为二进制文件 main,指定链接标志以减小二进制文件大小
RUN go build -ldflags="-s -w" -o /app/main main.go
# 第二阶段构建
# 构建完成后的最终镜像:使用 scratch 作为空镜像
FROM scratch
# 复制构建阶段中 Alpine 镜像中的 CA 证书到最终镜像中
COPY --from=builder /etc/ssl/certs/ca-certificates.crt /etc/ssl/certs/ca-certificates.crt
# 复制时区信息到最终镜像中
COPY --from=builder /usr/share/zoneinfo/Asia/Shanghai /usr/share/zoneinfo/Asia/Shanghai
# 设置环境变量 TZ 为 Asia/Shanghai
ENV TZ Asia/Shanghai
# 设置工作目录为 /app
WORKDIR /app
# 从构建阶段中复制编译好的可执行文件到最终镜像的工作目录
COPY --from=builder /app/main /app/main
# 容器启动时执行的命令为运行可执行文件 main
CMD ["./main"]
|
构建镜像
docker build -t your_dockerhub_username/image_name .
 这里指定用户名才可以推送到dockerhub
如果dockerfile不在项目根目录,可以指定dockerfile路径,
这里指定用户名才可以推送到dockerhub
如果dockerfile不在项目根目录,可以指定dockerfile路径,
docker build -t your_dockerhub_username/image_name -f ./xxx/Dockerfile .
如果注意,会看到 docker build 命令最后有一个 . 表示当前目录,而 Dockerfile 就在当前目录,因此不少初学者以为这个路径是在指定 Dockerfile 所在路径,这么理解其实是不准确的。如果对应上面的命令格式,你可能会发现,这是在指定 上下文路径。那么什么是上下文呢?
当我们进行镜像构建的时候,并非所有定制都会通过 RUN 指令完成,经常会需要将一些本地文件复制进镜像,比如通过 COPY 指令、ADD 指令等。而 docker build 命令构建镜像,其实并非在本地构建,而是在服务端,也就是 Docker 引擎中构建的。那么在这种客户端/服务端的架构中,如何才能让服务端获得本地文件呢?
这就引入了上下文的概念。当构建的时候,用户会指定构建镜像上下文的路径,docker build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
如果在 Dockerfile 中这么写:
COPY ./package.json /app/
这并不是要复制执行 docker build 命令所在的目录下的 package.json,也不是复制 Dockerfile 所在目录下的 package.json,而是复制 上下文(context) 目录下的 package.json。
跨平台
我们知道使用镜像创建一个容器,该镜像必须与 Docker 宿主机系统架构一致,例如 Linux x86_64 架构的系统中只能使用 Linux x86_64 的镜像创建容器
在 Docker 中,可以使用 –platform 标志来指定构建镜像的目标平台。这在你想要跨平台构建镜像时非常有用。可以通过以下方式指定平台:
docker build -t liuxian123/heelo1 --platform linux/amd64 .
也可以在dockerfile里面指定
构建完之后你就可以推送镜像到dockerhub,然后在服务器拉下来并且运行,这就是简易的docker部署
docker-compose
可以先看看这个
https://yeasy.gitbook.io/docker_practice/compose
docker-compose 可以快捷的创建多个容器
不同容器间,可以使用对方的名称来代替使用对方的虚拟网卡 ip 地址来访问
下面看个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
| version: '3.5'
# 网络配置
networks:
gophertok:
external: true
# 服务容器配置
services:
#jaeger链路追踪 — Jaeger for tracing
jaeger:
image: jaegertracing/all-in-one:latest
container_name: jaeger
restart: always
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
- "16686:16686"
- "14268:14268"
- "9411:9411"
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- ES_SERVER_URLS=http://elasticsearch:9200
- LOG_LEVEL=debug
networks:
- gophertok
#prometheus监控 — Prometheus for monitoring
prometheus:
image: prom/prometheus:v2.28.1
container_name: prometheus
environment:
# 时区上海 - Time zone Shanghai (Change if needed)
TZ: Asia/Shanghai
volumes:
- ./deploy/prometheus/server/prometheus.yml:/etc/prometheus/prometheus.yml
- ./data/prometheus/data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
restart: always
user: root
ports:
- 9090:9090
networks:
- gophertok
#查看prometheus监控数据 - Grafana to view Prometheus monitoring data
grafana:
image: grafana/grafana:8.0.6
container_name: grafana
hostname: grafana
user: root
environment:
# 时区上海 - Time zone Shanghai (Change if needed)
TZ: Asia/Shanghai
restart: always
volumes:
- ./data/grafana/data:/var/lib/grafana
ports:
- "3000:3000"
networks:
- gophertok
# #搜集kafka业务日志、存储prometheus监控数据 - Kafka for collecting business logs and storing Prometheus monitoring data
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.13.4
container_name: elasticsearch
user: root
environment:
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- TZ=Asia/Shanghai
restart: always
ports:
- "9200:9200"
- "9300:9300"
networks:
- gophertok
#查看elasticsearch数据 - Kibana to view Elasticsearch data
kibana:
image: docker.elastic.co/kibana/kibana:7.13.4
container_name: kibana
environment:
- elasticsearch.hosts=http://elasticsearch:9200
- TZ=Asia/Shanghai
restart: always
networks:
- gophertok
ports:
- "5601:5601"
depends_on:
- elasticsearch
#消费kafka中filebeat收集的数据输出到es - The data output collected by FileBeat in Kafka is output to ES
go-stash:
image: kevinwan/go-stash:1.0 # if you "macOs intel" or "linux amd"
#image: kevinwan/go-stash:1.0-arm64 # if you "macOs m1" or "linux arm"
container_name: go-stash
environment:
# 时区上海 - Time zone Shanghai (Change if needed)
TZ: Asia/Shanghai
user: root
restart: always
volumes:
- ./deploy/go-stash/etc:/app/etc
networks:
- gophertok
depends_on:
- elasticsearch
#收集业务数据 - Collect business data
filebeat:
image: elastic/filebeat:7.13.4
container_name: filebeat
environment:
# 时区上海 - Time zone Shanghai (Change if needed)
TZ: Asia/Shanghai
user: root
restart: always
entrypoint: "filebeat -e -strict.perms=false" #解决配置文件权限问题 - Solving the configuration file.sql permissions
volumes:
- ./deploy/filebeat/conf/filebeat.yml:/usr/share/filebeat/filebeat.yml
# 此处需指定docker的containers目录,取决于你docker的配置 - The containers directory of docker needs to be specified here, depending on your docker configuration
# 如snap安装的docker,则为/var/snap/docker/common/var-lib-docker/containers - Example if docker is installed by Snap /var/snap/docker/common/var-lib-docker/containers
# - /var/snap/docker/common/var-lib-docker/containers:/var/lib/docker/containers
- /var/lib/docker/containers:/var/lib/docker/containers
networks:
- gophertok
#zookeeper是kafka的依赖 - Zookeeper is the dependencies of Kafka
zookeeper:
container_name: zookeeper
build:
context: ./zookeeper
environment:
- TZ=Asia/Shanghai
privileged: true
networks:
- gophertok
ports:
- "2181:2181"
restart: always
#消息队列 - Message queue
kafka:
build:
context: ./kafka
container_name: kafka
ports:
- "9092:9092"
environment:
- KAFKA_ADVERTISED_HOST_NAME=kafka
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_AUTO_CREATE_TOPICS_ENABLE=false
- TZ=Asia/Shanghai
- ALLOW_PLAINTEXT_LISTENER=yes
restart: always
privileged: true
networks:
- gophertok
depends_on:
- zookeeper
# 映射mac docker容器位置
nsenter1:
image: justincormack/nsenter1
privileged: true
pid: host
|
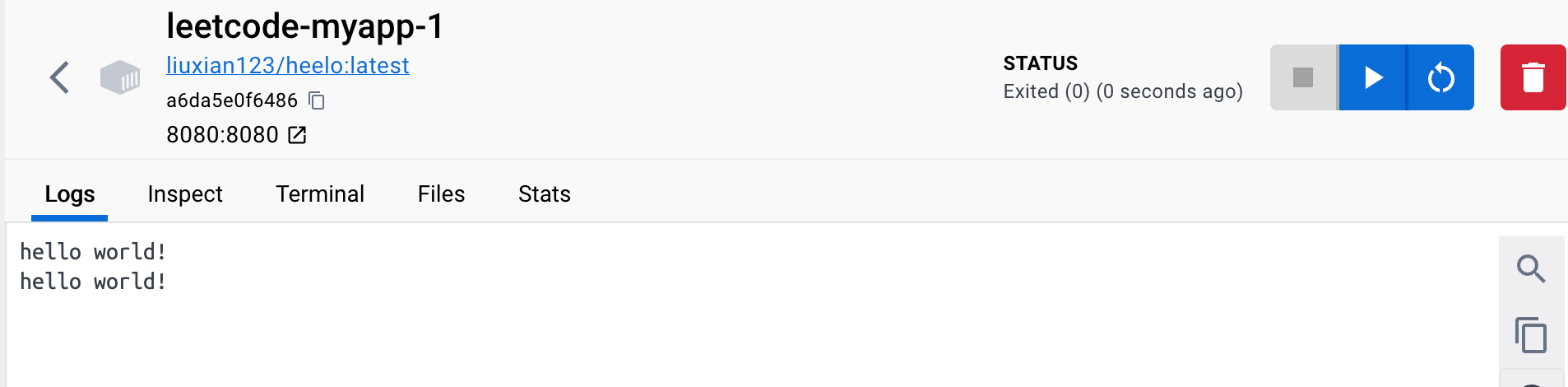
那我们也可以用docker-compose启动服务,这里会自动先拉取dockerhub上面的镜像
1
2
3
4
5
6
| version: '3'
services:
myapp:
image: your_dockerhub_username/image_name
ports:
- "8080:8080" # 如果你的 Go 程序在容器中监听的端口是 8080,将其映射到宿主机的 8080 端口
|
简易CI/CD
你想想,我们使用docker部署项目首先要编写dockerfile,然后构建镜像,再推送到docerhub,然后登服务器再拉取然后把服务跑起来,这样要是一个服务只搞一次这样做倒是没什么,但是如果是多个服务然后要不断修改,还这样修改一次就重复流程做一次吗,显然这样很搞人,所以我们可以借助一些自动化部署的工具
你想想,要是有这么一种工具,我们只需要修改后提交代码到github,然后就自动帮我们构建好镜像推送到dockerhub,然后还能远程ssh登录服务器帮我们删除老镜像,拉取新镜像然后重启。相当于我只管修改提交就完事了,构建部署我们完全不用管,它帮你做
这里推荐Github Action,因为方便简单,小项目绰绰有余
GItHub Actions
快速开始文档:https://docs.github.com/en/actions/quickstart
GItHub Actions是一个持续集成和持续交付的平台,能够让你自动化你的编译、测试和部署流程。
GitHub 提供 Linux、Windows 和 macOS 虚拟机来运行您的工作流程,或者您可以在自己的数据中心或云基础架构中托管自己的自托管运行器。
- Github Actions 的组成?
整体流程:
在github repo中特定事件发生时,workflow会被触发。
一个workflow由若干个job组成,这些job可以顺序运行,也可以并行运行。
每个job运行在自己的虚拟机runner或者容器中。
每个job由若干个step组成,这些step可以是运行脚本或者 执行一个action。
action是可以复用的拓展,用来简化workflow 。
这个慢慢了解吧,可以先只管用再了解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| name: Docker Build and Push XXXX # 工作流程的名称
on:
workflow_dispatch: # 通过 workflow_dispatch 手动触发工作流程
inputs:
parameter_name:
description: 'go'
required: true
jobs:
build-and-push-chat-rpc: # 构建和推送 chat-rpc 的作业
runs-on: ubuntu-latest # 在 Ubuntu 最新版本上运行
steps:
- name: Checkout the repository # 检出存储库
uses: actions/checkout@v2
- name: Login to Docker Hub # 登录到 Docker Hub
uses: docker/login-action@v1
with:
username: ${{ secrets.DOCKER_USERNAME }} # 使用存储库的 Docker 用户名
password: ${{ secrets.DOCKERHUB_TOKEN }} # 使用存储库的 Docker 访问令牌
- name: Set up QEMU # 设置 QEMU
uses: docker/setup-qemu-action@v1
- name: Set up Docker Buildx # 设置 Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Create and push chat-rpc Docker image # 创建并推送 chat-rpc Docker 镜像
uses: docker/build-push-action@v2
with:
context: . # Docker 上下文路径
file: ./server/chat/rpc/Dockerfile # Dockerfile 文件路径
push: true # 推送镜像到 Docker Hub
tags: ${{ secrets.DOCKERHUB_IMAGE }}chat-rpc:latest # 镜像的标签
platforms: linux/amd64,linux/arm64 # 构建多个架构的镜像
- name: executing remote ssh commands using password # 使用密码执行远程 SSH 命令
uses: appleboy/ssh-action@v0.1.10
with:
host: ${{ secrets.HOST }} # SSH 主机
username: ${{ secrets.USERNAME }} # SSH 用户名
password: ${{ secrets.PASSWORD }} # SSH 密码
port: ${{ secrets.PORT }} # SSH 端口
script: |
cd /home/project/gophertok # 执行远程服务器上的命令,此处进入特定目录
docker-compose stop chat-rpc
docker-compose rm -f chat-rpc
docker image rm ${{ secrets.DOCKERHUB_IMAGE }}chat-rpc:latest
docker-compose -f docker-compose.yaml up -d chat-rpc
|
参考
《Docker 技术入门与实战》第三版
https://www.cnblogs.com/crazymakercircle/p/15400946.html#autoid-h3-7-3-0
https://yeasy.gitbook.io/docker_practice/image/rm
作业
Lv0
多敲一下命令熟悉一下,然后有空可以看看书,搞完了之后不借助任何资料,就凭自己的理解回答以下问题:
- 删镜像和删容器的命令?
- exec 和 attach 进入容器有啥区别,推荐用哪一个?
- 编写Dockerfile的时候,COPY 和 ADD 有什么区别?
- Docker 三大底座的作用是什么,简单的描述一下
Lv1
使用 docker 部署自己的 go 程序
- 编写 dockerfile
- 构建镜像
- 推送镜像到 dockerhub
- 从服务器上拉取镜像并且启动容器
Lv2
编写多阶段构建的 Dockerfile,结合 Github Action 和 docker-compose 实现简易CI/CD
提交作业
格式:第十次作业-学号-姓名-Lv?
发送到邮箱:2926310865@qq.com